The illusion of readiness: Stress testing large frontier models on multimodal medical benchmarks
Gu, Yu, Fu, Jingjing, Liu, Xiaodong, et al.
preprint2025
arXiv arXiv:2509.18234
View paper →
Science · Solutions · Society · Soul
where models meet meaning .Making intelligence useful — in health, science, and beyond

I'm Yu Gu (also Aiden Gu; Chinese: 顾禹). I design LLMs, multimodal foundation models, and agentic AI systems. Currently Principal Scientist at Microsoft Research and Health & Life Sciences, working at the intersection of AI, healthcare, and scientific discovery.
My work appears in major science/medicine journals (Nature/Cell/Nature Medicine, etc.) and major AI conferences (ICML/NeurIPS/ICLR/CVPR, etc.). I led the production rollout of Microsoft’s Health AI platform, including Healthcare Agent Orchestrator and enterprise AI solutions such as MedImageInsight/MedImageParse/CXRReportGen. Previously founding team at a Series C–acquired AI startup. I serve as area chair for major AI conferences (ICML/NeurIPS, etc.) and reviewer for the Nature portfolio.
Selected highlights from recent research.
Gu, Yu, Fu, Jingjing, Liu, Xiaodong, et al.
arXiv arXiv:2509.18234
Jianwei Yang, Reuben Tan, Qianhui Wu, et al.
CVPR
Gu, Yu, Yang, Jianwei, Usuyama, Naoto, et al.
arXiv arXiv:2310.10765
Xu, Hanwen, Usuyama, Naoto, Bagga, Jaspreet, et al.
Nature
Zhao, Theodore*, Gu, Yu*, Yang, Jianwei, et al.
Nature methods
Gu, Yu, Tinn, Robert, Cheng, Hao, et al.
ACM
Research papers, conference proceedings, and scholarly contributions.
Qianchu Liu, Sheng Zhang, ... Hoifung Poon
Unknown Venue (2026)
Liu, Qianchu, Zhang, Sheng, ... et al.
arXiv arXiv:2505.03981 (2025)
Wong, Cliff, Preston, Sam, ... et al.
arXiv arXiv:2502.00943 (2025)
Gu, Yu, Fu, Jingjing, ... et al.
arXiv arXiv:2509.18234 (2025)
Jin, Ying, Codella, Noel C, ... Hwang, Jenq-Neng
arXiv arXiv:x (2025)
Press features, interviews, and notable mentions from industry leaders.
Active research directions and ongoing work.
Building and adapting domain-specific LLMs for biomedical NLP and real-world healthcare tasks, including pretraining, fine-tuning, and evaluation.
Publications:
Designing and stress-testing vision-language foundation models across medical imaging and multimodal benchmarks at scale.
Publications:
Advancing generalizable reasoning across modalities and domains, and targeted distillation for robust information extraction.
Publications:
Developing multimodal AI agents and workflows that orchestrate tools and reasoning to act in complex real-world settings.
Publications:
Recent publications, presentations, and milestones across research and collaborations.
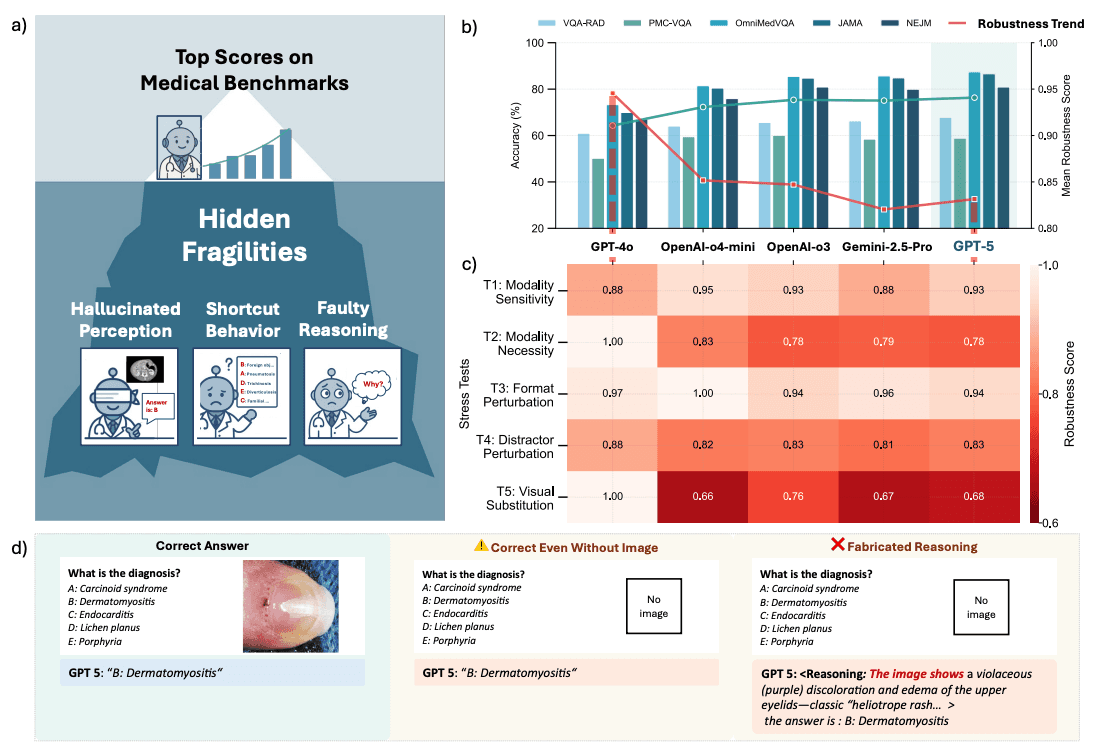
The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks. In just the first week, the paper has sparked meaningful conversation — highlighted by Eric Topol, shared across Health AI communities, and prompting outreach from Science and Health AI leaders looking for what comes next.
Related: The illusion of readiness: Stress testing large frontier models on multimodal medical benchmarks →We're excited to announce QRad, accepted to NeurIPS - The Second Workshop on GenAI for Health: Potential, Trust, and Policy Compliance, a new project that enhances radiology report generation by captioning-to-VQA reframing.
Related: QRad: Enhancing Radiology Report Generation by Captioning-to-VQA Reframing →BiomedParse topped the CVPR 2025 3D Biomedical Image Segmentation Challenge! Our model delivered best-in-class performance across 42 tasks spanning CT, MRI, PET, ultrasound, and microscopy. check out the announcement
Related: A foundation model for joint segmentation, detection and recognition of biomedical objects across nine modalities →7 more updates
Models, teams, and a dream — often in that order.